Je známo, že při překladu nejde ani tak o překládání slov jako o převod významů. Proto překladatelům klasické slovníky pomůžou jen do určité míry: jdou totiž od slova k významu, zatímco překladatel často potřebuje jít od významu ke slovu. Jaké slovníky a nástroje mu v tom můžou usnadnit práci? A dočkáme se dotisku skvělého Klégrova Tezauru jazyka českého?
Vezměte si klasickou situaci: přesně víte, co chce autor říct, a hledáte slova, do kterých byste jeho sdělení „zabalili“ v cílovém jazyce. Napadají vás české ekvivalenty slov originálu, ale žádné z nich není to pravé. Zvažujete různá synonyma včetně vyjádření víceslovných a idiomatických. Možná nepohrdnete ani výrazem významově užším nebo širším. Napadá vás ledacos, ale stále to není ono, a tak si chcete vypomoct nějakým tím slovníkem.
V tomto případě vám nejlépe poslouží některý z tzv. onomaziologických slovníků. To je právě typ slovníku, který postupuje od významu ke slovu. Literatura uvádí tři druhy:
- slovník synonym,
- obrazový slovník,
- tezaurus, tedy slovník, který slova a slovní spojení podává tematicky podle významů – nejznámější je anglický Rogetův tezaurus a čeští uživatelé si oblíbili dnes již beznadějně rozebraný Tezaurus jazyka českého, který má výstižný podtitul Slovník českých slov a frází souznačných, blízkých a příbuzných.

Kromě tištěných slovníků můžeme dnes slova významově blízká vyhledávat i pomocí elektronických nástrojů včetně běžného fulltextového hledání ve výkladovém slovníku. K tomu se ale dostanu později. Nejdřív se podívejme na jednotlivé typy slovníků a uveďme si konkrétní osvědčené tituly. Všechny si trošičku otestujeme: ve všech budeme hledat stejné slovo.
Slovníky synonym
Když hledáme vhodné slovo, sáhneme možná nejdřív po slovníku synonym. Dnes je na trhu v podstatě jediný titul, Slovník českých synonym a antonym od nakladatelství Lingea s 34 tisíci hesly. Možná také ještě někde seženete Slovník českých synonym Karla Paly a Jana Všianského od nakladatelství NLN, který nabízí něco přes 22 tisíc hesel. Nejvíc hesel ale najdete na portálu Nechybujte.cz společnosti Lingea: je jich tam celkem 64 tisíc.
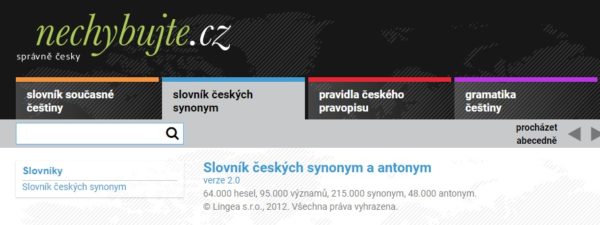
Podívejme se, jaká synonyma uvádí portál Nechybujte.cz ke slovu mizera. Je jich celkem pět a kliknutním na kterékoliv z nich otevřeme příslušné heslo, pod kterým najdeme další synonyma (a antonyma).
(hovor. hanl.) padouch, (expr.) bídák, lotr, (neutr.) darebák, ničema ≠ (expr.) klaďas
Slovník českých synonym
Obrazové slovníky
Obrázkovými slovníky asi nejčastěji listují studenti cizích jazyků, protože jednak v nich najdou slovní zásobu seřazenou pěkně tematicky (např. zahrada anebo supermarket), jednak jim ilustrace můžou pomoci se zapamatováním slov. Osvědčenou klasikou jsou obrázkové slovníky nakladatelství Duden, které vyšly v mnoha jazykových mutacích, např. anglická verze vyšla naposledy v roce 1995 jako The Oxford-Duden Pictorial English Dictionary. Od té doby slovník bohužel poněkud zastaral. Přesto se v něm dá najít ledacos.

Jednou jsem například potřeboval do angličtiny přeložit „divadelní tahy“. Jistě by se to dalo najít i na internetu, ale pro mě bylo v danou chvíli nejrychlejší vyhledat ve výše zmíněném slovníku dvoustranu Theatre, najít tahy na obrázku a hned jsem věděl, že to jsou „fly lines“ nebo jen „lines“ (mimochodem pohledem do chorvatsko-německé verze slovníku zjišťuji, že německy to je „Züge“ a chorvatsky „povlake“).
Nevýhodou obrázkových slovníků je samozřejmě skutečnost, že zachycují jen konkréta. Zřejmě největším slovníkem s češtinou je pětijazyčný Obrazový slovník nakladatelství Universum z roku 2007. Obsahuje 6000 obrázků a 35 tisíc slov v každém jazyce.
Tezaury
Tezaury v českém prostředí velkou tradici nemají. Prvním slovníkem, který stojí za zmínku, je Český slovník věcný a synonymický, který vycházel v letech 1969-1986 a skládá se ze čtyř svazků (tří svazků tematických, které čítají celkem 1594 stran, a jednoho svazku s abecedním rejstříkem).

Hlavní autor Jiří Haller bohužel v průběhu jeho tvorby zemřel a plánovaný čtvrtý tematický svazek již nevyšel. Slovník se dá i dnes celkem snadno sehnat v antikvariátech.
Když v rejstříku vyhledáme slovo mizera, najdeme odkaz na dvě hesla v 3. svazku: na heslo „ničema“ a „zlý člověk“. Heslo „ničema“ zabírá zhruba jeden a půl strany a najdeme v něm přibližně 350 výrazů. Heslo „zlý člověk“ pak zabírá asi půl strany a najdeme v něm slova jako necita, surovec nebo bestie.

Hallerův slovník má sice i dnes obrovskou hodnotu, ale v podstatě jde o torzo, a tak se prvním uceleným, dokončeným a aktuálním pojmovým slovníkem stal až v roce 2007 Tezaurus jazyka českého, jehož autorem je profesor Aleš Klégr. Tezaurus jazyka českého byl vytvořen po vzoru Rogetova tezauru. Právě z něj se v první fázi hesla překládala do češtiny. V druhé fázi vznikala hesla podle českých pramenů a do nich byl zapracován překlad z angličtiny. Výsledný tezaurus má celkem 885 hesel o cca 200 tisících slovních jednotek (tematická část má 861 stran, abecední rejstřík 663 stran, je to tedy pořádný otesánek). Čeština tak získala slovníkovou příručku, která do té doby chyběla, a zařadila se k nemnoha jazykům, které tímto druhem slovníku disponují.
Když vyhledáme slovo mizera v rejstříku Tezauru jazyka českého, najdeme odkazy na čtyři hesla, nebo vlastně podhesla: neřád, ničema, nízký člověk a podvodník. Podívejme se na první z nich. Je součástí hesla bezcennost.

Další pojmové slovníky
Kromě Tezauru jazyka českého si mnoho překladatelů oblíbilo další dvě příručky. Tou první je Šmírbuch jazyka českého Patrika Ouředníka, který se zaměřuje na nekonvenční češtinu, tedy na výrazy slangové, vulgární, žargonové apod. Pro mnoho literárních a filmových překladatelů tak je Šmírbuch jednou z nejdůležitějších pomůcek. Jednotlivá hesla spisovné češtiny jako třeba polepšovna, políbit nebo policista jsou řazena abecedně a druhou část (od druhého vydání) tvoří abecední rejstřík všech „nekonvenčních“ výrazů, tedy např. bengo, fízl a chlupatej. S neformálním výrazivem je ale ta potíž, že se vyvíjí velmi rychle, a proto takováto příručka nutně musí zastarávat rychleji než slovník převážně spisovného, neutrálního jazyka. Šmírbuch naposledy vyšel v roce 2016, a tak nebude problém ho sehnat.
Ve Šmírbuchu slovo „mizera“ nenajdete, ale najdete v něm slovo „ničema“ a pod ním více než 60 ekvivalentů včetně slov ksindl, hajzl, děvka, kurva, šmejd, veš, ventra, mršina, mrcha, svině, sviňák, zasranec, smrad, ale také například plivajz, vošklíbr, krysa Vasilisa nebo saracénská šavle.
Druhou oblíbenou pomůckou je pátý svazek Slovníku české frazeologie a idiomatiky, který má přímo podtitul Onomaziologický slovník. Shrnuje věcné rejstříky předchozích svazků SČFI a jedná se vlastně o pojmový slovník či tezaurus, který se omezuje na idiomy a frazémy. Takže například pod heslem být lhostejný najdeme výrazy jako být / bejt někomu buřt / egál / fuk / šumafu(k), být někomu cizí, bejt někomu putna nebo nebýt / nebejt na někoho / něco zvědavý / zvědavej. Slovník vyšel v roce 2016, a tak ho běžně seženete.

Elektronické nástroje
Možná řeknete, že papírové slovníky jsou přežitek. Pro mě tedy ne – slovníky rád listuji a nacházím v nich souvislosti mezi jednotlivými slovy, které by mi v elektronické verzi téhož slovníku unikly. Ale jiné souvislosti a hlavně vyčerpávající přehled výskytů daného slova většinou získáme jen fulltextovým prohledáváním elektronického slovníku. To je navíc výrazně rychlejší.
Mnoho překladatelů přišlo na to, že v elektronických výkladových slovnících můžou provádět i „onomaziologické vyhledávání“, tedy že v nich můžou vyhledávat synonyma či jiná slova významově blízká. Vezměme si opět slovo mizera a zkusme ho vyhledat ve Slovníku spisovného jazyka českého, Příručním slovníku jazyka českého (zaškrtneme volbu Hesla a heslové stati, respektive Heslové stati) a ve Slovníku současné češtiny (rubrika Výklady).
hadrlump, holomek, mizera, *mizerák, pacholek, potvora, potvorník, prevít, prezent, *smotlacha, šuft
Slovník spisovného jazyka českého
kanálie, mizera, mizerák, poplésti, potrhati, potvorník, pramizera, psina, psota, servilní, šuft, šufťák, uschovávati, všivota
Příruční slovník jazyka českého
dobytek, holomek
Slovník současné češtiny
V některých případech je samozřejmě nalezené slovo součástí příkladového materiálu (např. poplésti, uchovávati), ale vidíme, že ve většině případů jsme skutečně našli slova významově blízká. V tomto konkrétním případě nám nalezená slova příliš nepomohou, ale jindy výsledky vyhledávání skutečně oceníte. Jde především o to, abychom našli vhodné slovo, které se bude často vyskytovat v definici hledaných slov. V našem případě by bylo lepší zadat darebák. Ve výsledcích by potom byla slova jako grázl, gauner, chuligán, lump, neřád, syčák nebo šmejd. A kdybychom chtěli hledat cíleně slangové výrazy, bylo by ideální, kdybychom měli elektronickou verzi výkladového slovníku slangů. Takový slovník, pokud vím, v elektronické verzi neexistuje. Kdybych ale tento typ vyhledávání potřeboval častěji, nejspíš bych uvažoval o naskenování a převodu (OCR) některého vhodného slovníku – samozřejmě jen pro osobní potřebu, protože jinak bych se dopustil porušení autorského zákona.
Možná byste dokázali doplnit další on-line slovníky, ve kterých se dá takto vyhledávat. Já už uvedu jen projekt Čeština 2.0, ve kterém je sice velké množství příležitostných, autorských a efemérních slov, ale i tam najdete lecjakou perlu.
Funkce Thesaurus korpusového portálu Sketch Engine
Možností, o které ví málokdo, je funkce Thesaurus korpusového portálu Sketch Engine. Chytrý algoritmus najde slova významově blízká čistě na základě kvantitativních vlastností příslušných lexémů. Pokud jste si ke korpusům na portálu Sketch Engine zařídili přístup, stačí vybrat některý z velkých korpusů (čím větší a tematicky relevatnější, tím lepší), kliknout na Thesaurus a zadat hledané slovo.
Výsledky se potom zobrazí jednak v tabulce, jednak v „obláčku slov“ (word cloud). Podívejme se opět na slovo mizera (jedná se o výřez – tabulka ve skutečnosti pokračuje a přednastavený počet zobrazených slov navíc můžeme změnit). Jednou z výhod je, že výsledky rozhodně nejsou nijak cenzurované či umravněné.

Tezaury pro 21. století
Možná už delší dobu marně sháníte Tezaurus jazyka českého a říkáte si, jestli se nechystá jeho dotisk. Mám dobrou zprávu: chystá se něco ještě lepšího – jeho digitalizace a propojení s Českým slovníkem věcným a synonymickým. Záleží ovšem na tom, zda budou úspěšné dvě žádosti o grant. Jeden grantový projekt se jmenuje Digitální tezaurus češtiny a má „poskytovat tezaurové služby […] online širokému spektru uživatelů – od širší veřejnosti se zájmem o český jazyk, přes překladatele, jazykovědce až po aplikace třetích stran“. Druhý projekt se jmenuje Elektronický Český slovník věcný a synonymický jako online lexikální databáze a jeho cílem je digitalizovat uvedený slovník a propojit jej s Tezaurem. Držme tedy oběma projektům palce. Jestliže se je podaří realizovat, překladatelé a další služebníci slova získají vynikající elektronické pomůcky, které budou skýtat ještě větší možnosti než jejich papírové předlohy.
Za mnoho cenných informací k problematice onomaziologických slovníků děkuji profesoru Aleši Klégrovi.
Příspěvek Tak trochu jiné slovníky pochází z TranslatoBlog